【Leecode】Hot100刷题笔记
一、数组
二、链表
24. 两两交换链表节点
可以优化成k个一组交换交换时需要考虑的问题:
1、是否满足有两个节点(node1、node2)来交换
2、交换时必须要前一个节点辅助交换
3、交换前必须记录node2的下一个节点
解题思路:
1.要一个哨兵节点辅助交换(问题2)
2.每次只用关注node2是否为空即可(问题1)
3.交换节点之前记录下一个节点(问题3)
public ListNode swapPairs(ListNode head) {
if(head==null||head.next==null) return head;
ListNode dumpy = new ListNode(0,head);
ListNode prev=dumpy,node1=head,node2=head.next;
//dumpu->1->2->3->4->null
while(node1!=null&&node2!=null){
ListNode nxt = node2.next;
// 交换
node1.next=nxt;
prev.next=node2;
node2.next=node1;
if(nxt==null){
break;
}
// 重新命名
prev = node1;
node1 = nxt;
node2 = nxt.next;
}
return dumpy.next;
}25. K 个一组翻转链表
思路:本质就是链表翻转。重点在于如何确定翻转的范围:
1、用长度数字进行遍历,记录这段起始点curr_head,到长度k后,翻转curr_head到curr这段链表。
2、翻转后如何拼接链表:此时翻转后变成三段(前,curr,后),需要用哨兵节点记录上一段的最后一个节点拼接前和curr段;翻转前记录后的第一个节点。反转后拼接上curr+后。
3、注意:(i + 1) % k == 0来判断。
public ListNode reverseKGroup(ListNode head, int k) {
int len = 0;
ListNode senti = new ListNode(0, head), curr = head;
while (curr != null) {
curr = curr.next;
len++;
}
ListNode curr_head = head, nxt = null, h_senti = senti;
curr = head;
for (int i = 0; i < len; i++) {
if ((i + 1) % k == 0) {
nxt = curr.next;
curr.next = null;
// 翻转后变成前,curr,后三段链表。
// curr_head反转后从第一个变成最后一个:需要链接到后面的组,并让senti=curr_head
// 拼接-->前+curr
h_senti.next = reverse(curr_head);
// 拼接-->curr+后
curr_head.next = nxt;
h_senti = curr_head;
// 重新定义各个节点
curr_head = nxt;
curr = nxt;
} else {
curr = curr.next;
}
}
return senti.next;
}138. 随机链表的复制
思路:一模一样的复制,若没有random节点,直接遍历复制val即可。有random节点,必须知道在原链表中的节点的random指向哪个节点。做一个交错的复制链表,通过遍历时取next就能取到。但是要注意random为null的情况。
在每个原节点后插入复制节点形成交错链表,这样原节点的复制节点就是它的next,原节点的random指向的节点的复制节点就是random.next。通过三次遍历完成:第一次交错复制、第二次设置random指针、第三次分离链表。
public Node copyRandomList(Node head) {
Node h =head;
// 1.先一个间隔一个的在原链表插入复制一个
while(h!=null){
Node tmp = new Node(h.val);
tmp.next=h.next;
h.next=tmp;
h=h.next.next;
}
// 2.复制random字段,原链表节点对应的下一个
h=head;
while(h!=null){
Node copy = h.next;
// 注意random可能是null,没有下一个节点
copy.random = h.random==null?null:h.random.next;
h=copy.next;
}
// 3.利用dummy拆出节点
h=head;
Node dummy = new Node(0);
Node tmp_dummy=dummy;
while(h!=null){
Node copy = h.next;
tmp_dummy.next = copy;
tmp_dummy=copy;
h.next = copy.next;
h=h.next;
}
return dummy.next;
}148. 排序链表
思路:链表排序,通过分治思想,把链表切割看成两个链表,然后递归使左右有序,合并有序链表即可
public ListNode sortList(ListNode head) {
if(head==null||head.next==null) return head;
ListNode mid = mid(head);
mid = sortList(mid);
head = sortList(head);
return merge(mid,head);
}23. 合并K个升序链表->1
思路:分治思想,把数组切割看成两个数组,递归合并左右数组,到数组只剩两个时进行合并有序链表
通过下标指定即可。
public ListNode mergeKLists(ListNode[] lists) {
int len = lists.length;
if(len==0) return null;
return mergeLists(lists,0,len-1);
}
ListNode mergeLists(ListNode[] lists,int l,int r){
if(l==r) return lists[l];
ListNode a = mergeLists(lists,l,(l+r)/2);
ListNode b = mergeLists(lists,(l+r)/2+1,r);
return merge(a,b);
}146. LRU 缓存
思路:借助LinkedHashMap(插入有序,最近最少使用的就在第一个)。注意Hashmap的API,containsKey(),map的iterator()先用keySet()进行获取
三、二叉树
108. 将有序数组转换为二叉搜索树
思路:有序数组转二叉搜索树,即每次切分数组为两份,分别递归构建成左右子树。小的部分构建左子树,大的部分构建右子树。
注意:停止时机:左右index相等时创建节点返回,右节点小于左节点的时候不满足返回null
public TreeNode sortedArrayToBST(int[] nums) {
return build(nums,0,nums.length-1);
}
TreeNode build(int[] nums,int l,int r){
if(r<l) return null;
if(l==r) return new TreeNode(nums[l]);
int mid = l+(r-l)/2;
TreeNode node = new TreeNode(nums[mid]);
node.left = build(nums,l,mid-1);
node.right = build(nums,mid+1,r);
return node;
}114. 二叉树展开为链表
思路:题目要求将二叉树展开为链表,即按照按后序遍历顺序展开,展开后的结构应为所有左子树为空、仅用右指针连接的链表。我们可以利用一个全局变量
prev来记录当前已经构建好的链表的头节点。对原树进行后序遍历(右子树 → 左子树 → 根节点),在遍历过程中依次将节点重新连接。
- 当前节点的右指针指向
prev(已构建的链表头),左指针置空;- 更新
prev为当前节点,使其成为新的链表头。
TreeNode ans = null;
public void flatten(TreeNode root) {
dfs(root);
}
void dfs(TreeNode root) {
if (root == null) {
return;
}
dfs(root.right);
dfs(root.left);
root.right = this.ans;
root.left = null;
this.ans = root;
}105. 从前序与中序遍历序列构造二叉树
思路:根据前序(根节点在最前)和中序(根节点在中间)特点,分割左右两个数组,然后分别递归构建左右子树。
1、先用获取前序(根节点在最前),把中序数组分割为两个子数组
2、用序数组分割的两个子数组的长度,将前序数组分割为左右两个子数组
3、分别将上述两个子数组递归构建左右子树
4、在数组长度为0时返回null
思考:为什么长度为1时进行mid+1取子数组也不会出现out length:因为先取inorder,mid只能为0为,mid+1=1,取(1,length)实际就是空数组了,就结束递归。
public TreeNode buildTree(int[] preorder, int[] inorder) {
if(preorder.length==0) return null;
// 前序 第一个 切分 中序左右子树
int mid = find(inorder, preorder[0]);
int[] l_inorder = Arrays.copyOfRange(inorder, 0, mid);
int[] r_inorder = Arrays.copyOfRange(inorder, mid + 1, inorder.length);
// 根据中序的左右子树,切分前序数组
int[] l_pre = Arrays.copyOfRange(preorder, 1, 1 + l_inorder.length);
int[] r_pre = Arrays.copyOfRange(preorder, 1 + l_inorder.length, preorder.length);
TreeNode root = new TreeNode(preorder[0]);
root.left = buildTree(l_pre, l_inorder);
root.right = buildTree(r_pre, r_inorder);
return root;
}
int find(int[] nums,int num){
for(int i=0;i<nums.length;i++){
if(nums[i]==num) return i;
}
return -1;
}437. 路径总和 III
思路:要求路径和是从上到下满足targetsum,其实就是前缀和之差,递归二叉树,用curr记录到了的前缀和,用一个map存前缀个数,然后通过map.get(curr-targetsum)若有则表示有一段是满足和为targetsum的。
注意:
1、要先get后再进行存储个数(特殊情况tree=[1],targetSum=0)
2、当前节点结束后要把这包含这个节点的前缀和从map中取消。
3、map的key要设置为Long
class Solution {
HashMap<Long,Integer> map = new HashMap();
int ans=0;
public int pathSum(TreeNode root, int targetSum) {
map.put(0L,1);
dfs(root,targetSum,0L);
return this.ans;
}
void dfs(TreeNode root,int targetSum,Long curr){
if(root==null) return;
curr+=root.val;
this.ans+=map.getOrDefault(curr-targetSum,0);
map.merge(curr,1,Integer::sum);
dfs(root.left,targetSum,curr);
dfs(root.right,targetSum,curr);
map.merge(curr,-1,Integer::sum);
}
}236. 二叉树的最近公共祖先
思路:最次返回当前节点。
如果当前节点 root == null,返回 null(空树无结果);
如果当前节点 root == p 或 root == q,返回 root(找到目标节点,向上传递);
递归遍历左子树,得到结果 left;递归遍历右子树,得到结果 right;
对 left 和 right 做核心判断:
情况 1:left != null 且 right != null → 当前节点就是最近公共祖先(p、q 分别在当前节点的左右子树);
情况 2:left != null 且 right == null → 返回left(p、q 都在左子树,继续向上传递);
情况 3:left == null 且 right != null → 返回right(p、q 都在右子树,继续向上传递);
情况 4:left == null 且 right == null → 返回null(当前子树无目标节点)。
public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
if(root==null) return root;
if(root==p||root==q) return root;
TreeNode l = lowestCommonAncestor(root.left,p,q);
TreeNode r = lowestCommonAncestor(root.right,p,q);
if(l!=null&&r!=null) return root;
if(l!=null) return l;
if(r!=null) return r;
return null;
}124. 二叉树中的最大路径和
思路:最大路径和是一条路径上的和,每一个节点都可能成为路径的 “顶点”(即路径以该节点为中心,向左右子树延伸)。
通过后序递归遍历,返回当前节点的最大有效和 (注意:这个地方返回的最长和是要么左要么右,因为要满足向上回溯的路径连续性,只需要向上返回当前节点下的最优,但如果左右都小于0直接返回0)。且每次每个节点要再计算当前节点作为 “顶点” 时的路径和(根节点值 + 左子树有效贡献 + 右子树有效贡献),并更新全局最大值。
class Solution {
int max = Integer.MIN_VALUE;
public int maxPathSum(TreeNode root) {
dfs(root);
return max;
}
int dfs(TreeNode root) {
if (root == null)
return 0;
int l = dfs(root.left);
int r = dfs(root.right);
int curr_path = root.val+l+r;
max = Math.max(Math.max(curr_path,curr),max);
return Math.max(0,Math.max(l,r)+root.val);
}
}四、图论
200. 岛屿数量
思路:以第一个(0,0)为入口直接遍历图。若发现一个'1',则是一个新的岛屿,ans++,然后递归的把这个岛屿(上下左右遍历为'1'的格子)赋值为'2',表示这个岛屿已经被发现过了(停止遍历当前岛屿条件:整周围只有'0'和'2'了)。
class Solution {
public int numIslands(char[][] grid) {
int ans=0;
for(int i=0;i<grid.length;i++){
for(int j=0;j<grid[0].length;j++){
if(grid[i][j]=='1'){
dfs(grid,i,j);
ans++;
}
}
}
return ans;
}
void dfs(char[][] grid,int i,int j){
if(i<0||i>=grid.length||j<0||j>=grid[0].length||grid[i][j]!='1'){
return;
}
grid[i][j]='2';
dfs(grid,i+1,j);
dfs(grid,i,j+1);
dfs(grid,i,j-1);
dfs(grid,i-1,j);
}
}994. 腐烂的橘子
思路:因为每一分钟,所有腐烂的橘子要同时感染其周围的,所以要按照一个批次的烂橘子进行感染。先初始记录存在的烂橘子list。以这个list去做层序遍历,一次遍历就是一分钟,每次遍历把感染的新的加入到新的list,这批完后老的list就不要了,改为用新的list去遍历。
注意:要记录感染的个数和原新鲜的个数,一致才表示全部感染了。此外注意停止感染的边界(下标越界或者不是新鲜橘子)
class Solution {
public int orangesRotting(int[][] grid) {
int fresh=0,badNum=0;
int ans=0;
List<int[]> bad = new ArrayList();
for(int i=0;i<grid.length;i++){
for(int j=0;j<grid[0].length;j++){
if(grid[i][j]==1) fresh++;
if(grid[i][j]==2) bad.add(new int[]{i,j});
}
}
// 层序遍历,一次就是一分钟
while(bad.size()!=0){
List<int[]> tmp = new ArrayList();
for(int[] curr:bad){
makeBad(grid,curr[0],curr[1]-1,tmp);
makeBad(grid,curr[0],curr[1]+1,tmp);
makeBad(grid,curr[0]-1,curr[1],tmp);
makeBad(grid,curr[0]+1,curr[1],tmp);
}
bad=tmp;
if(tmp.size()!=0) ans++;
// 新的坏果,之前的不用了
badNum+=bad.size();
}
return fresh==badNum?ans:-1;
}
void makeBad(int[][] grid,int i,int j,List<int[]> tmp){
// 是否还在格子内,且当前是否有好橘子
if(i<0||j<0||i>=grid.length||j>=grid[0].length||grid[i][j]!=1){
return;
}
grid[i][j]=2;
tmp.add(new int[]{i,j});
}
}207. 课程表
208. 实现 Trie (前缀树)
思路:用一个26路的树结构(a-z)来记录存入的值。
在存入时注意,未使用过的子节点为空,需要手动初始化。且在使用时要以上一层.child[i]来访问当前层,若为空,进行初始化。
此外用一个字段记录当前节点是否为一个单词的结束位置。因为不同单词会重复,有可能长的包含短的如app和apple。
五、回溯
回溯要点:
- 当前操作:确定当前要做的操作是什么
- 子问题:构造当前节点之后的部分
- 下一个 问题
- 结束条件
46. 全排列

思路:需要递归的去找所有的可能,用一个index记录到了哪个下标。
- 当前操作:确定当前位置可能的数(index)。当前的值可以是和其本身以及其之后的值sawp。
- for(int i=index;i<nums.length;i++)
- 下一个操作:对当前位置之后的数进行排列(index+1)
- 结束条件:当index为数组长度(递归到数组最后),就将当前数组为一个结果加入返回值列表。
class Solution {
public List<List<Integer>> permute(int[] nums) {
List<List<Integer>> ans = new ArrayList();
back(nums,0,ans);
return ans;
}
void back(int[] nums,int index,List<List<Integer>> ans){
if(index==nums.length){
List<Integer> tmp = new ArrayList();
for(int i=0;i<nums.length;i++){
tmp.add(nums[i]);
}
ans.add(tmp);
}
for(int i=index;i<nums.length;i++){
swap(nums,i,index);
back(nums,index+1,ans);
swap(nums,i,index);
}
}
}78. 子集

思路:安装回溯要素考虑。
- 当前操作:选还是不选当前值加入此趟结果
- 下一个操作:将当前位置之后的进行同样的回溯
- 停止结果:是否到数组最后
class Solution {
public List<List<Integer>> subsets(int[] nums) {
List<List<Integer>> ans = new ArrayList();
back(nums,0,ans,new ArrayList<Integer>());
return ans;
}
void back(int[] nums,int index,List<List<Integer>> ans,List<Integer> path){
if(index==nums.length){
ans.add(new ArrayList(path));
return;
}
path.add(nums[index]);
back(nums,index+1,ans,path);
path.removeLast();
back(nums,index+1,ans,path);
}
}17. 电话号码的字母组合
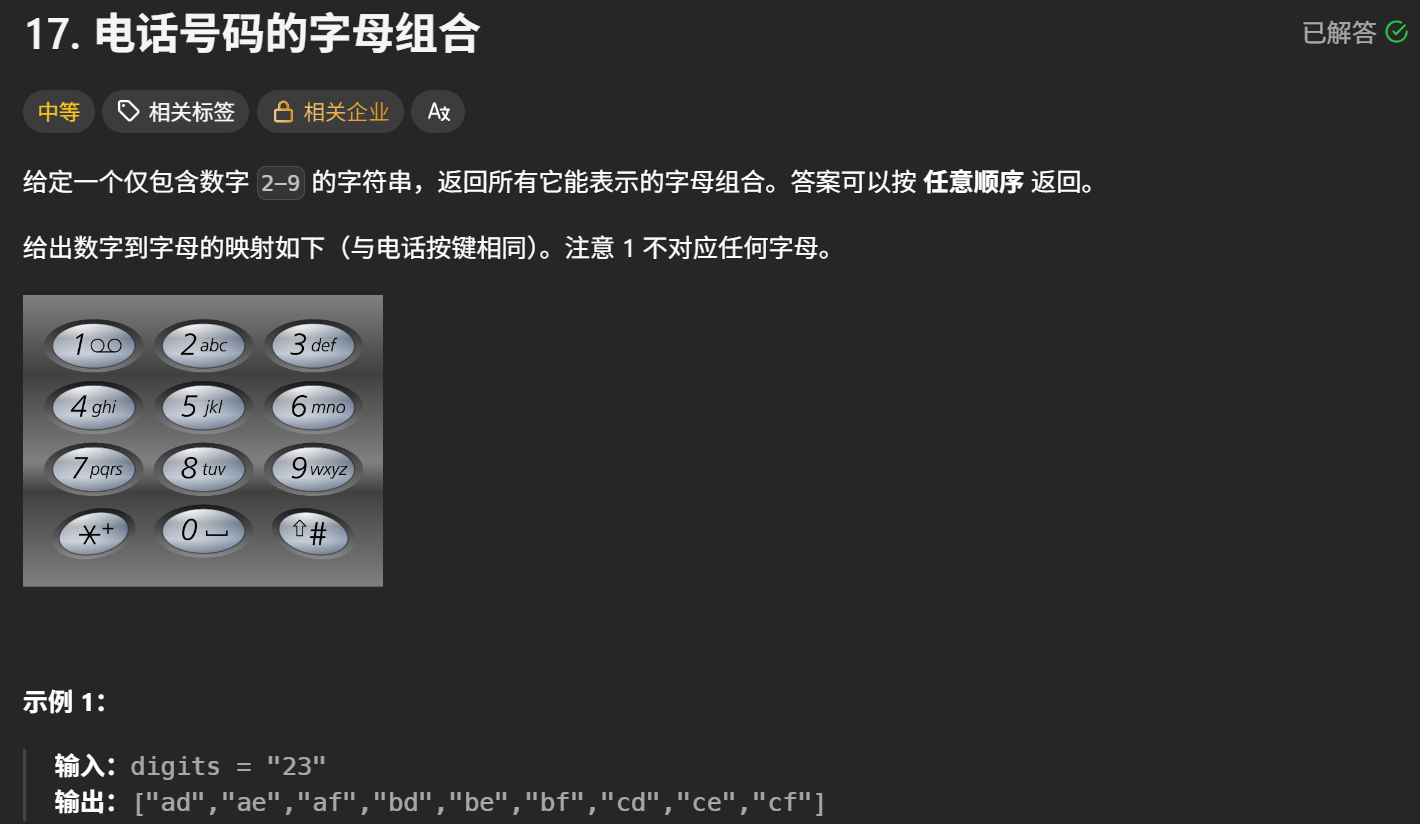
思路:回溯的去枚举,用一个path记录
当前index按钮下选择了哪个字母,然后回溯index+1后的,用完后移除path。
- 当前操作:选当前index的哪个字母。每个都有可能,使用for枚举。当前用完后移除。
- 下一个操作:将当前位置之后的进行同样的回溯
- 停止结果:是否到数组最后
class Solution {
char[][] nums = new char[][] { {}, {}, { 'a', 'b', 'c' }, { 'd', 'e', 'f' }, { 'g', 'h', 'i' }, { 'j', 'k', 'l' },
{ 'm', 'n', 'o' }, { 'p', 'q', 'r', 's' }, { 't', 'u', 'v' }, { 'w', 'x', 'y', 'z' } };
public List<String> letterCombinations(String digits) {
List<String> ans = new ArrayList();
List<Character> path = new ArrayList();
back(digits.toCharArray(),0,ans,path);
return ans;
}
void back(char[] digits,int index,List<String> ans,List<Character> path){
if(index==digits.length){
StringBuilder tmp = new StringBuilder();
for(int i=0;i<path.size();i++){
tmp.append(path.get(i));
}
ans.add(tmp.toString());
return;
}
char curr = digits[index];
// 选哪一个
for(int i=0;i<nums[curr-'0'].length;i++){
path.add(nums[curr-'0'][i]);
back(digits,index+1,ans,path);
path.removeLast();
}
}
}39. 组合总和

思路:回溯的去枚举,用一个path记录
当前index按钮是否选择当前数字,sum记录当前的路径的数的和,然后回溯index+1后的,用完后移除path。
- 当前操作:选当前的数字加入,因为
可以重复(2,2,2)= 6,以当前下标,不用i+1进行后续回溯,结束条件为sum>target或sum=target或i==candidate.length。- 下一个操作:将当前位置的进行同样的回溯
- 停止结果:是否到数组最后,sum是否大于target。sum是否等于target
class Solution {
public List<List<Integer>> combinationSum(int[] candidates, int target) {
List<List<Integer>> ans=new ArrayList();
List<Integer> path = new ArrayList();
back(candidates,0,target,0,ans,path);
return ans;
}
void back(int[] candidates,int index,int target,int sum,List<List<Integer>> ans,List<Integer> path){
if(sum==target){
ans.add(new ArrayList(path));
return;
}
if(index==candidates.length||sum>target){
return;
}
for(int i=index;i<candidates.length;i++){
sum+=candidates[i];
path.add(candidates[i]);
back(candidates,i,target,sum,ans,path);
path.removeLast();
sum-=candidates[i];
}
}
}22. 括号生成

思路:回溯的去找可能的组合。l和r记录当前左右括号个数。 选l(左括号)还是r(右括号),只要l<n,l都可以选。只要r<l,r都可以选
- 当前操作:当前选l还是r
- 下一个操作:将当前位置的进行同样的回溯
- 停止结果:l和r是否到n/2了
class Solution {
public List<String> generateParenthesis(int n) {
List<String> ans= new ArrayList();
List<Character> path = new ArrayList();
trace(n,0,0,ans,path);
return ans;
}
void trace(int n,int l,int r,List<String> ans,List<Character> path){
if(l+r==n*2){
StringBuilder tmp = new StringBuilder();
for(int i=0;i<path.size();i++){
tmp.append(path.get(i));
}
ans.add(tmp.toString());
}
// 选l还是r,只要l<n,l都可以选。只要r<l,r都可以选
if(l<n){
path.add('(');
trace(n,l+1,r,ans,path);
path.removeLast();
}
if(r<l){
path.add(')');
trace(n,l,r+1,ans,path);
path.removeLast();
}
}
}79. 单词搜索

思路:网格中每一个点都有可能是起点。遍历网格,从每个点作为起点开始trace回溯判断是否是word。
- 当前操作:当前
网格位置(i,j)是否与word中的index一样。若当前一样,就进行网格上下左右下一个元素对比index++。子回溯上下左右有一个满足即可。当前网格位置用完后标记为已使用,用完后撤回标记。- 下一个操作:将当前位置的
word位置index+1后的进行同样的回溯- 停止结果:
index==word.length或i,j超限或当前网格元素与word的index位置元素不一样
class Solution {
boolean ans =false;
public boolean exist(char[][] board, String word) {
// 为了方便,直接用数组代替哈希表
int[] cnt = new int[128];
for (char[] row : board) {
for (char c : row) {
cnt[c]++;
}
}
// 优化一
char[] w = word.toCharArray();
int[] wordCnt = new int[128];
for (char c : w) {
if (++wordCnt[c] > cnt[c]) {
return false;
}
}
// 优化二
if (cnt[w[w.length - 1]] < cnt[w[0]]) {
w = new StringBuilder(word).reverse().toString().toCharArray();
}
for(int i=0;i<board.length;i++){
for(int j=0;j<board[0].length;j++){
if(trace(board,i,j,word,0)){
return true;
}
}
}
return false;
}
boolean trace(char[][] board,int i,int j,String word,int index){
if(i<0||j<0||i>=board.length||j>=board[0].length){
return false;
}
if(board[i][j]!=word.charAt(index)){
return false;
}
if(index==word.length()-1){
return true;
}
board[i][j]=0;
boolean find1 = trace(board,i+1,j,word,index+1);
boolean find2 = trace(board,i-1,j,word,index+1);
boolean find3 = trace(board,i,j+1,word,index+1);
boolean find4 = trace(board,i,j-1,word,index+1);
board[i][j] = word.charAt(index);
return find1||find2||find3||find4;
}
}131. 分割回文串

思路:从下标start=0开始,枚举每个区间for(int end=start;...);若当前区间【start,end】为回文串,则对end+1的串进行子回溯。
- 当前操作:从start的位置开始,枚举start->length长度,看【start,end】是否为回文串。
- 下一个操作:若当前【start,end】是回文串,将当前位置的
end+1后的进行同样的回溯- 停止结果:
strat==length
class Solution {
public List<List<String>> partition(String s) {
List<List<String>> ans = new ArrayList();
List<String> path = new ArrayList();
trace(s,0,ans,path);
return ans;
}
void trace(String s,int start,List<List<String>> ans,List<String> path){
if(start==s.length()){
ans.add(new ArrayList(path));
}
for(int end=start;end<s.length();end++){
if(para(s,start,end)){
path.add(s.substring(start,end+1));
trace(s,end+1,ans,path);
path.removeLast();
}
}
}
}51. N 皇后

思路:每一行,枚举每一列的元素看是否能当Queen。要满足 1.与之前的不在同一列用boolean数组记忆之前Queen在的列位置
boolean[] col。2.不在同一正反对角线(如何判断?),用两个boolean[n*2-1] 记录对应的正反对角线是否有Queen在。3.用一个int[] queen记录每行,对应的Queen的下标。
- 当前操作:从当前行的第一列开始枚举,看当前位置是否可以放Queen,若可以就进行下一行(
row+1)同样的操作。- 下一个操作:若当前【start,end】是回文串,将当前位置的
end+1后的进行同样的回溯- 停止结果:
row==n
class Solution {
public List<List<String>> solveNQueens(int n) {
List<List<String>> ans = new ArrayList();
List<String> path = new ArrayList();
//1.记录是否在正反对角线是否有皇后了,互相攻击。
boolean[] dial1 = new boolean[n*2-1],dial2=new boolean[n*2-1];
//2.记录是否在某列已经有皇后了
boolean[] col = new boolean[n];
//记录每行的哪一列为Q,也可用于判断同列是否攻击
int[] queens = new int[n];
trace(n,0,ans,queens,dial1,dial2,col);
return ans;
}
void trace(int n,int row,List<List<String>> ans,int[] queens,boolean[] dial1,boolean[] dial2,boolean[] col){
if(row==n){
List<String> tmp = new ArrayList();
// 遍历每行进行构造,构造的是每一行
for(int i=0;i<n;i++){
char[] curr = new char[n];
Arrays.fill(curr,'.');
curr[queens[i]]='Q';
tmp.add(new String(curr));
}
ans.add(tmp);
}
for(int i=0;i<n;i++){
if(!col[i]&&!dial1[row+i]&&!dial2[row-i+n-1]){
queens[row] = i;
col[i]=dial1[row+i]=dial2[row-i+n-1]=true;
trace(n,row+1,ans,queens,dial1,dial2,col);
col[i]=dial1[row+i]=dial2[row-i+n-1]=false;
}
}
}
}六、二分查找
35. 搜索插入位置
思路:其实就是通过二分找到第一个大于等于target的位置。注意:就算找到了也不要return。
class Solution {
public int searchInsert(int[] nums, int target) {
int mid=0,l=0,r=nums.length-1;
while(l<=r){
mid=(l+r)/2;
if(nums[mid]<target){
l=mid+1;
}else if(nums[mid]>target){
r=mid-1;
}
}
return l;
}
}74. 搜索二维矩阵
思路:遍历即可
34. 在排序数组中查找元素的第一个和最后一个位置
思路:只需要去找第一个大于等于该元素,以及第一个大于等于该元素加一的即可。
注意,找到后,先看<第一个大于等于该元素>是否存在。
l==nums.length --> 所有元素全部小于该元素
nums[l]!=nums.length --> 所有元素都不等于该元素
l==0 --> 所有元素全部大于该元素
class Solution {
public int[] searchRange(int[] nums, int target) {
int l = loewe(nums,0,nums.length-1,target);
int r = loewe(nums,0,nums.length-1,target+1);
if(nums.length==l||nums[l]!=target) return new int[]{-1,-1};
return new int[]{l,r-1};
}
int loewe(int[] nums,int i,int j,int target){
int mid=0;
while(i<=j){
mid=(j-i)/2+i;
if(nums[mid]<target){
i=mid+1;
}else {
j=mid-1;
}
}
return i;
}
}153. 寻找旋转排序数组中的最小值
思路:由于这个数组是旋转的 【4,5,6,7,0,1,2】,不是强有序,但是数组被最后一个数把数组切割为了两分,一半比最后一个大,一半比最后一个小。
因此最小值就是第一个小于等于
2的元素(即0)。用二分查找不断缩小范围:若nums[mid] > 最后一个数,说明在左半,往右找;否则往左找。最后left指向的就是最小值。旋转后的数组以最后一个数为基准,可以映射成一个布尔数组
[true, true, true, true, false, false, false](true表示大于最后一个数,false表示小于等于最后一个数)。
本题就是要找第一个false的位置,也就是最小值。用二分查找寻找这个边界即可。
class Solution {
public int findMin(int[] nums) {
int mid =0,l=0,r=nums.length-1;
while(l<=r){
mid=l+(r-l)/2;
if(nums[mid]>nums[nums.length-1]){
l=mid+1;
}else{
r=mid-1;
}
}
return nums[l];
}
}33. 搜索旋转排序数组
思路:基于153,找到旋转排序数组的中点后,看target在哪个部分,然后使用二分查找找即可。
class Solution {
public int search(int[] nums, int target) {
int split = findMin(nums);
int ans=-1;
if(target>nums[nums.length-1]){
ans = lowe(nums,0,split-1,target);
}else{
ans = lowe(nums,split,nums.length-1,target);
}
return ans;
}
int lowe(int[] nums,int l,int r,int target) {
int mid=0;
while(l<=r){
mid=l+(r-l)/2;
if(nums[mid]<target){
l=mid+1;
}else{
r=mid-1;
}
}
if(nums.length==l||nums[l]!=target) return -1;
return l;
}
int findMin(int[] nums) {
int mid=0,l=0,r=nums.length;
while(l<=r){
mid=l+(r-l)/2;
if(nums[mid]>nums[nums.length-1]){
l=mid+1;
}else{
r=mid-1;
}
}
return l;
}
}七、栈、堆
20. 有效的括号
思路:就用一个栈去匹配,若是左括号,就加入;若是右括号就进行匹配若不匹配就直接返回false。注意循环条件用下标。另外,每次取stack最后一个时注意判空。
class Solution {
public boolean isValid(String s) {
char[] cs = s.toCharArray();
ArrayDeque<Character> stack = new ArrayDeque();
stack.addLast(cs[0]);
int i=1;
while(i<s.length()){
char curr=cs[i];
if(curr=='[' || curr=='{' || curr=='('){
stack.addLast(curr);
}else{
if(stack.isEmpty()){
return false;
}
char last = stack.getLast();
switch(curr){
case ')':
if(last=='(') stack.removeLast();
else return false;
break;
case ']':
if(last=='[') stack.removeLast();
else return false;
break;
case '}':
if(last=='{') stack.removeLast();
else return false;
break;
}
}
i++;
}
return stack.isEmpty();
}
}155. 最小栈
思路:最小栈,即一个数据结构能维护存在数据的最小值。
用一个链表,链表每个节点记录它及其后面的节点的最小值(每次插入这个节点时比一下之前最小和当前val即可)。使用头插法,这样每次删除和插入时都操作头结点。
class MinStack {
class Node{
int val;
int preMin;
Node next;
}
Node stack;
public MinStack() {
}
public void push(int val) {
if(stack==null){
stack=new Node();
stack.val = val;
stack.preMin=val;
}else{
Node newOne = new Node();
newOne.val=val;
newOne.preMin=Math.min(val,stack.preMin);
newOne.next=stack;
stack=newOne;
}
}
public void pop() {
stack=stack.next;
}
public int top() {
return stack.val;
}
public int getMin() {
return stack.preMin;
}
}
/**
* Your MinStack object will be instantiated and called as such:
* MinStack obj = new MinStack();
* obj.push(val);
* obj.pop();
* int param_3 = obj.top();
* int param_4 = obj.getMin();
*/394. 字符串解码
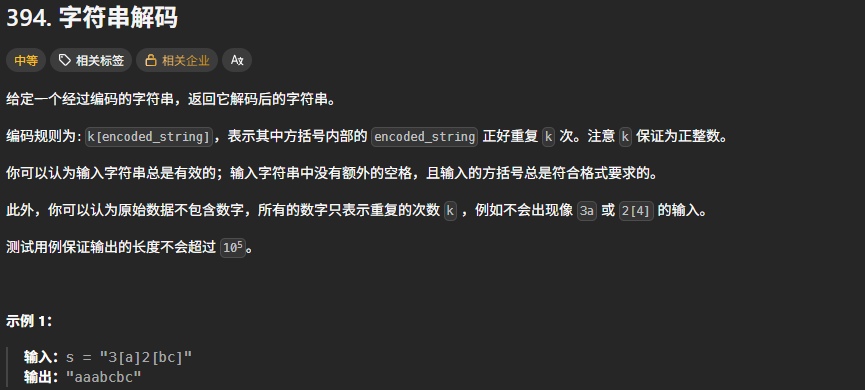
思路:本题主要是遍历这个字符串。有四种情况:1.数字、2.字母、3.'[' 、4.']'。用一个全局的index表示当前到哪儿了。然后进行递归。
1.若是数字,就循环的进行处理,记录一个k,然后因为从左是从高位开始,每次循环就把上一次的k*10;
2.若是字母,直接append
3.若是'[',进入递归,把内部解析后返回回来,然后根据k,用repeat(string,int),进行重复叠加
3.若是']',表示递归应该结束了。
class Solution {
public String decodeString(String s) {
char[] cs = s.toCharArray();
return decode(cs);
}
int index=0;
String decode(char[] cs){
int k=0;
StringBuilder ans = new StringBuilder();
while(index<cs.length){
char curr = cs[index];
index++;
if(Character.isDigit(curr)){
k = k*10+curr-'0';
}else if(Character.isLetter(curr)){
ans.append(curr);
}else if(curr=='['){
String tmp = decode(cs);
ans.repeat(tmp,k);
// 把k置为0
k=0;
}
// 为']'时退出
else{
break;
}
}
return ans.toString();
}739. 每日温度
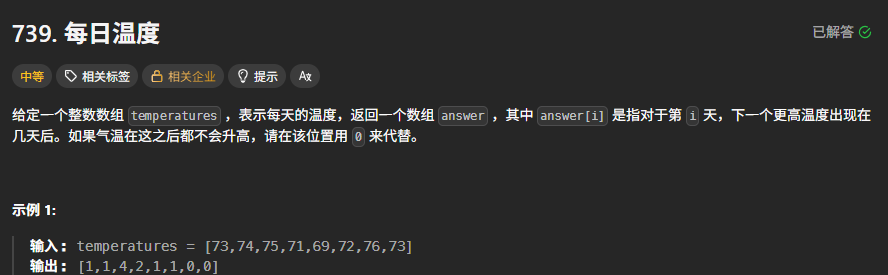
思路:从后向前,维护一个最大值栈。当前位置一直比,删除栈里面比他小的,最后若栈空了,则他的后面是没有比他大的,ans=0,反之,ans=栈的last - index
class Solution {
public int[] dailyTemperatures(int[] temperatures) {
int[] ans =new int[temperatures.length];
ArrayDeque<Integer> s = new ArrayDeque();
int index = temperatures.length-1;
s.addLast(index--);
while(index>=0){
while(!s.isEmpty()&&temperatures[s.getLast()]<=temperatures[index]){
s.removeLast();
}
ans[index] = s.isEmpty()?0:s.getLast()-index;
s.addLast(index);
index--;
}
return ans;
}
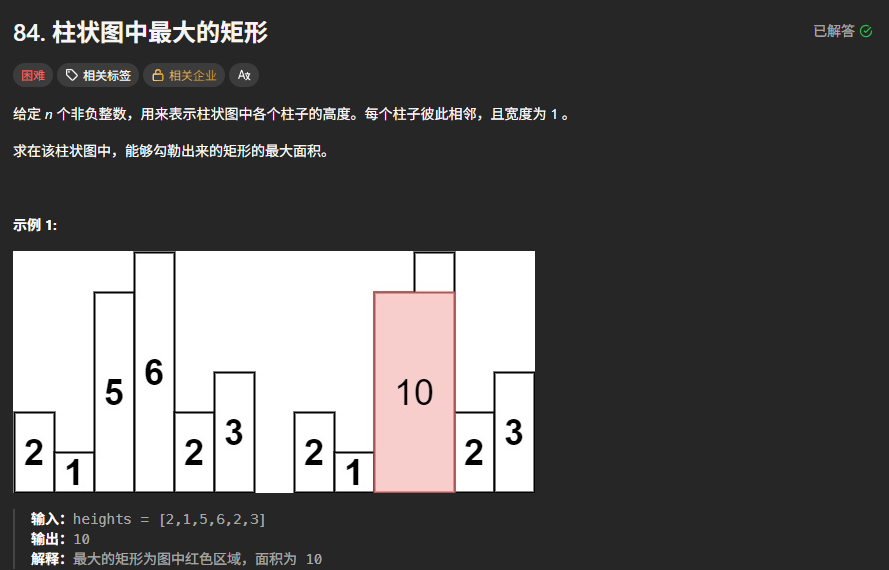
}84. 柱状图中最大的矩形
思路:分别找到当前柱子前后距离最近的比他矮的柱子,比当前柱子低或一样高的即可。
// 因为要矩形面积,比当前高的没意义,只有宽才有意义。把每个柱子能构成的最大矩形面积都找到即可。
// 注意若左或右都比当前柱子高,应该是-1或length
class Solution {
public int largestRectangleArea(int[] heights) {
int ans=0;
ArrayDeque<Integer> post = new ArrayDeque();
ArrayDeque<Integer> pre = new ArrayDeque();
int[] pres = new int[heights.length],posts = new int[heights.length];
int i = heights.length-1;
posts[i] = heights.length;
post.addLast(i--);
while(i>=0){
while(!post.isEmpty()&&heights[post.getLast()]>=heights[i]){
post.removeLast();
}
//空了表示后面的全部比当前柱子高
posts[i] = post.isEmpty()?heights.length:post.getLast();
post.addLast(i);
i--;
}
i = 0;
pres[i]=-1;
pre.addLast(i++);
while(i<heights.length){
while(!pre.isEmpty()&&heights[pre.getLast()]>=heights[i]){
pre.removeLast();
}
//空了表示前面的全部比当前柱子高
pres[i] = pre.isEmpty()?-1:pre.getLast();
pre.addLast(i);
i++;
}
for( i=0;i<heights.length;i++){
ans=Math.max(ans,(posts[i]-pres[i]-1)*heights[i]);
}
return ans;
}
}215. 数组中的第K个最大元素
思路:快速排序。快速排序的逻辑是:随机选择一个元素,把这个元素放到他应该在的位置;然后以这个元素为partition将数组分割为左右为比他大/小的,然后递归进行。故找第k个用快速排序不用吧数组全部排序完,就可以找到。注意,第k个转换到下标的话要用nums.length-k。

class Solution {
public int findKthLargest(int[] nums, int k) {
int ans = quickSort(nums,0,nums.length-1,nums.length-k);
return ans;
}
int quickSort(int[] nums,int l, int r,int k){
if(l>=r) return nums[l];
int left=l+1,right=r,index=l;int curr = nums[l];
// 把patition放到指定位置
while(left<=right){
while(left<=right&&nums[left]<curr){
left++;
}
while(left<=right&&nums[right]>curr){
right--;
}
if(left<=right){
int tmp =nums[left];
nums[left]=nums[right];
nums[right] = tmp;
left++;right--;
}
}
// 因为nums[l]在的位置是比curr小的,只能与right去换
nums[l] = nums[right];
nums[right]=curr;
// nums[l] = curr;
if(k==right) return curr;
else if(k>right) return quickSort(nums,right+1,r,k);
else return quickSort(nums,l,right-1,k);
}
}347. 前 K 个高频元素
思路:将出现频率相同的元素按组统计到一起,然后遍历前k个即可。
先用map统计每个元素出现的评率,然后用列表数组(List[] buckets= new List[Maxtimes])来将出现频率相同的元素放到同一个LIst下,Maxtimes就是频率最高的数字,下标就表示这个LIst里面的数出现的评率。最后倒着遍历即可。
class Solution {
public int[] topKFrequent(int[] nums, int k) {
HashMap<Integer,Integer> map =new HashMap();
// 统计每个元素出现评率
for(int i=0;i<nums.length;i++){
map.merge(nums[i],1,Integer::sum);
}
int maxCnt = Collections.max(map.values());
// 将元素按出现**次数**的整理成List(创建一个最大次数为长度的数组)
ArrayList<Integer>[] bucket = new ArrayList[maxCnt+1];
for(int i=0;i<bucket.length;i++){
bucket[i] = new ArrayList();
}
for(Integer key:map.keySet()){
bucket[map.get(key)].add(key);
}
int[] ans = new int[k];
int j=0;
// 第三步:倒序遍历 buckets,把出现次数前 k 大的元素加入答案(bucket的数组下标即为出现的次数)
for(int i = maxCnt;i>=0&&j<k;i--){
// 第x大的.注意题目保证答案唯一,一定会出现某次循环结束后 j 恰好等于 k 的情况
for(Integer curr:bucket[i]){
ans[j++]=curr;
}
}
return ans;
}
}八、贪心算法
121. 买卖股票的最佳时机

思路:遍历数组,然后需要比较选出然后出现过的
最小的值,然后每次当前值-最小值比较 即可。
class Solution {
public int maxProfit(int[] prices) {
int premin = prices[0],ans=0;
for(int i=0;i<prices.length;i++){
ans = Math.max(ans,prices[i]-premin);
premin = Math.min(prices[i],premin);
}
return ans;
}
}55. 跳跃游戏

思路:
class Solution {
public boolean canJump(int[] nums) {
int toMax = 0,curr=0;
for(int i=0;i<nums.length;i++){
toMax=Math.max(toMax,i+nums[i]);
if(toMax<i+1){
return false;
}
}
return true;
}
}55. 跳跃游戏

思路:遍历数组,然后用一个字段,通过比较,记录
当前能到的最远的位置-->toMax = i+nums[i]。如何不到达?toMax<i或toMax=i&&i不是最后一个。
class Solution {
public boolean canJump(int[] nums) {
int toMax = 0,curr=0;
for(int i=0;i<nums.length;i++){
toMax=Math.max(toMax,i+nums[i]);
if(toMax<i||(toMax==i&&i!=nums.length-1)){
return false;
}
}
return true;
}
}45. 跳跃游戏 II

思路:和上一题类似,需要在遍历时记录能到的最远位置。
但是区别是。
判断改为若上一次移动的位置到了,移动次数+1,然后把新的能移动到的最远位置改为新的。
且不用遍历到
i<nums.length,到i<nums.length-1即可,因为到了最后一个就不用算次数了。
class Solution {
public int jump(int[] nums) {
int curr=0,toMax=0,ans=0;
for(int i=0;i<nums.length-1;i++){
toMax=Math.max(toMax,i+nums[i]);
if(curr==i){
curr=toMax;
ans++;
}
}
return ans;
}
}763. 划分字母区间
思路:用一个new int[26]数组 ,来记录s中每个字符在的最远的下标。然后遍历数组,用一个值来维护能走的最远下标,若end==i表示这个区间的这批数据只在这里了。就可以加入答案了。
class Solution {
public List<Integer> partitionLabels(String s) {
int[] cnt = new int[26];
for(int i=0;i<s.length();i++){
cnt[s.charAt(i)-'a'] = i;
}
List<Integer> ans =new ArrayList();
int end=0,l=-1;
for(int i=0;i<s.length();i++){
end = Math.max(end,cnt[s.charAt(i)-'a']);
if(end==i){
ans.add(end-l);
l=end;
}
}
return ans;
}
}九、动态规划
十、技巧
136. 只出现一次的数字
思路:利用异或运算 a⊕a=0 的性质,我们可以用异或来「消除」所有出现了两次的元素,最后剩下的一定是只出现一次的元素。其中用到了异或运算的交换律 a⊕b=b⊕a,以及结合律 (a⊕b)⊕c=a⊕(b⊕c)

class Solution {
public int singleNumber(int[] nums) {
int ans=0;
for(int i=0;i<nums.length;i++){
ans=ans^nums[i];
}
return ans;
}
}169. 多数元素
思路:打擂台,。记录一个数的个数,初始第一个元素。若相等cnt++,不等就cnt--。cnt为0了就换元素,并且cnt置为1。最后存在擂台上的元素为结果。
class Solution {
public int majorityElement(int[] nums) {
int curr=nums[0],cnt=0;
for(int i=0;i<nums.length;i++){
if(curr==nums[i]){
cnt++;
}else if(cnt>0){
cnt--;
}else{
curr=nums[i];
cnt=1;
}
}
return curr;
}
}75. 颜色分类
思路:三指针遍历即可
class Solution {
public void sortColors(int[] nums) {
int red=0,white=0,blue=nums.length-1;
while(white<=blue){
if(nums[white]==0){
swap(nums,white,red);
red++;white++;
}else if(nums[white]==1){
white++;
}else{
swap(nums,white,blue);
blue--;
}
}
}
}287. 寻找重复数
思路: 这是数组里面寻找重复数,可以把其看做找循环链表的入口节点。i = num[num[i]]是快节点,i=num[i]是慢节点。
为什么可以这么做?因为给定一个包含
n + 1个整数的数组nums,其数字都在[1, n]范围内(包括1和n)。故通过num[num[i]]去访问一定是可以访问到的。
class Solution {
public int findDuplicate(int[] nums) {
int i=0,j=0;
i=nums[i];j=nums[nums[j]];
while(i!=j){
i=nums[i];
j=nums[nums[j]];
}
int s=0;
while(s!=i){
s=nums[s];
i=nums[i];
}
return i;
}
}31. 下一个排列

思路:这道题主要是要找到第一个拐点。
1、从右往左找到第一个“升序点”(即 nums[i] < nums[i+1]),因为第一个升序点的
右边一定是是递减的,已经是最大排列;2、然后在 i 的右侧递减区间中,从右往左找到第一个比 nums[i] 大的数,与其交换,让当前位尽量“小幅度变大”;
3、最后把 i 右边的部分整体反转,使其从递减变为递增(
最大变成最小了),从而得到刚好比当前排列大的最小字典序排列。
// 13542
class Solution {
public void nextPermutation(int[] nums) {
int i=0;
// 1.找到第一个nums[i-1]>nums[i]的点,可以最小的变大
for( i=nums.length-2;i>=0;i--){
// 有不符合排序的点。退出
if(nums[i]<nums[i+1]){
break;
}
}
// 2.找到i这个拐点,其右边一定是递减的。不然i不会是第一个拐点
if(i>=0){
// 若有这个拐点,去找第一个最近的拐点,把大的换到前面去
int j=nums.length-1;
while(nums[i]>=nums[j]){
j--;
}
swap(nums,i,j);
}
// 3.若不满足第一步的有大小拐点,则i=-1
reverse(nums,i+1,nums.length-1);
}
private void swap(int[] nums, int i, int j) {
int tmp = nums[i];
nums[i] = nums[j];
nums[j] = tmp;
}
private void reverse(int[] nums, int left, int right) {
while (left < right) {
swap(nums, left++, right--);
}
}
}十一、排序
冒泡排序
void sort(int[] nums){
int len=nums.length;
for(int i=0;i<len;i++){
for(int j=1;j<len-i;j++){
if(nums[j-1]>nums[j]){
int tmp=nums[j-1];
nums[j-1]=nums[j];
nums[j]=tmp;
}
}
}
}快速排序
思路:通过分治的思想,先把数组以pivot分割为左小于,右大于的数组,然后递归的再把左右进行相同操作实现排序。
public void quickSort(int[] nums) {
quickSort(nums,0,nums.length-1);
}
int sort(int[] nums,int l, int r){
if(l==r) return nums[l];
int left=l+1,right=r,index=l;int curr = nums[l];
// 把patition放到指定位置
while(left<=right){
while(left<=right&&nums[left]<curr){
left++;
}
while(left<=right&&nums[right]>curr){
right--;
}
if(left<=right){
int tmp =nums[left];
nums[left]=nums[right];
nums[right] = tmp;
left++;right--;
}
}
nums[l] = nums[right];
nums[right]=curr;
sort(nums,right+1,r);
sort(nums,l,right-1);
}